Massive-Training Artificial Neural Network (MTANN) Trained with a Small Number of Cases for Enhancement of Nodules and Suppression of Vessels in Thoracic CT: Phantom Experiments
A massive-training artificial neural network (MTANN) is a trainable, highly nonlinear filter consisting of a linear-output multilayer artificial neural network model. For enhancement of nodules and suppression of vessels, we used 10 nodules and 10 non-nodule images as training cases for MTANNs. The MTANN is trained with a large number of input subregions selected from the training cases and the corresponding pixels in teaching images that contain Gaussian distributions for nodules and zero for non-nodules. We trained three MTANNs with different numbers (one, nine, and 361) of training samples (pairs of the subregion and the teaching pixel) selected from the training cases. To investigate the basic characteristics of the trained MTANNs, we applied the MTANNs to simulated CT images containing various-sized model nodules (spheres) with different contrasts and various-sized model vessels (cylinders) with different orientations. In addition, we applied the trained MTANNs to non-training actual clinical cases with 59 nodules and 1,726 non-nodules. In the output images for the simulated CT images by use of the MTANNs trained with small numbers (one and nine) of subregions, model vessels were clearly visible and were not removed; thus, the MTANNs were not trained properly. However, in the output image of the MTANN trained with a large number of subregions, various-sized model nodules with different contrasts were represented by light nodular distributions, whereas various-sized model vessels with different orientations were dark and thus were almost removed. This result indicates that the MTANN was able to learn, from a very small number of actual nodule and non-nodule cases, the distinction between nodules (sphere-like objects) and vessels (cylinder-like objects). In non-training clinical cases, the MTANN was able to distinguish actual nodules from actual vessels in CT images. For 59 actual nodules and 1,726 non-nodules, the performance of the MTANN decreased as the number of training samples (subregions) in each case decreased. The MTANN can be trained with a very small number of training cases (10 nodules and 10 non-nodules) in the distinction between nodules and non-nodules (vessels) in CT images. Massive training by scanning of training cases to produce a large number of training samples (input subregions and teaching pixels) would contribute to a high generalization ability of the MTANN.
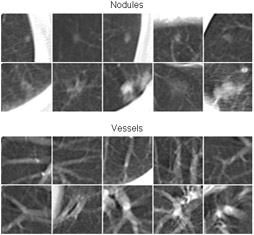
Ten nodule images (top two rows) and ten non-nodule images (bottom tow rows) including vessels used for training an MTANN.

Simulated CT image (left) that contains various-sized model nodules with different contrasts and various-sized model vessels with different orientations, and the corresponding output image (right) of the MTANN trained with ten actual nodules and ten actual vessel images.